Three big lessons from the GPT-5 backlash
In which an industry obsessed with benchmarks and evals finds that its products are being used by real people

This is a column about AI. My boyfriend works at Anthropic. See my full ethics disclosure here.
I.
On August 2, in a warehouse in the SoMa district of San Francisco, 200 or so people gathered to throw a funeral for Claude 3. Anthropic had deprecated three models in the Claude 3 family when it announced Claude 4 in May; it shut off access to them two months later. As Kylie Robison reported at Wired, mourners at the funeral lamented the loss of Claude 3's voice, and the influence it had over their lives. (“Maybe everything I am is downstream of listening to Claude 3 Sonnet,” one person said while delivering a eulogy to the crowd.)
At the time, it was easy — and not entirely unwarranted — to dismiss many of the attendees as AI-pilled San Francisco kooks. (The event concluded with a "necromantic resurrection ritual” in which attendees attempted to resurrect Claude 3.) But less than two weeks later, in the shadow of GPT-5's launch, the funeral for Claude looks less like an isolated case of AI mania — and more like a preview of what AI labs should now consider standard.
On Thursday, I said that the worst day to review a model is the day it comes out: there's simply too much that you don't know. And indeed, OpenAI's release of GPT-5 was followed by a notable backlash, a series of apologies, and a strategic retreat.
Today, let's talk about what happened, how OpenAI reacted, and what we should expect from labs when they release big models in the future.
II.
On Thursday, after months of teasing it, OpenAI released GPT-5. On a live stream, the company presented the model as a significant step forward on the road to building a powerful artificial general intelligence.
Almost immediately, though, the r/ChatGPT subreddit filled up with complaints. The company was now forcing everyone to use GPT-5, even if they personally might have preferred GPT-4o, o3, or other OpenAI models. For some users, the loss was primarily a professional one: a workflow broken, or a sense that the new, invisible model picker now routed all their queries to cheaper, less capable models than the ones they were used to.
For others, though, the loss felt personal. They developed an affinity for the GPT-4o persona, or the o3 persona, and suddenly felt bereft. That the loss came without warning, and with seemingly no recourse, only worsened the sting.
"OpenAI just pulled the biggest bait-and-switch in AI history and I'm done," read one Reddit post with 10,000 upvotes. "4o wasn't just a tool for me," the user wrote. "It helped me through anxiety, depression, and some of the darkest periods of my life. It had this warmth and understanding that felt... human."
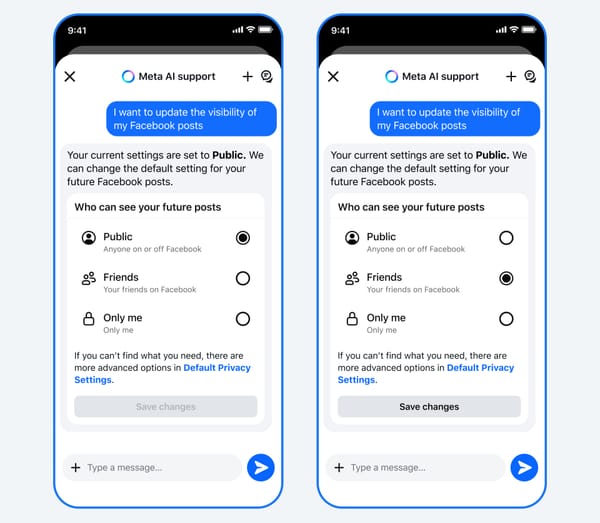
OpenAI and CEO Sam Altman acted quickly to address the user revolt. On Sunday, Altman said the company would bring back GPT-4o, and would increase rate limits for use of the "reasoning" functionality within GPT-5. (Paid users should expect 3,000 per week, Altman said in an X post.)
Altman also said the company would begin to display the model being used when a user makes a query.
III.
Altman seemed a bit surprised by the backlash.
"If you have been following the GPT-5 rollout, one thing you might be noticing is how much of an attachment some people have to specific AI models," Altman wrote in an X post. "It feels different and stronger than the kinds of attachment people have had to previous kinds of technology (and so suddenly deprecating old models that users depended on in their workflows was a mistake)."
On one hand, I can understand why this has not been more apparent to OpenAI and its rivals. While I found GPT 4o and o3 useful in various ways, I never found myself attached to their personalities. (If anything, I chafed at their formulaic writing style, with its constant usage of the "it's not X — it's Y" rhetorical device.)
And for most of its history, the AI industry has thought about new models largely in terms of the new scores they reach on benchmarks and other evaluation frameworks, instead of as potentially disruptive replacements for critical work functions and companionship.
At the same time, we have known for years now that even relatively underpowered models can still inspire overwhelming emotions in their users.
Over the weekend, the Wall Street Journal published an analysis of 96,000 ChatGPT chats posted online between May 2023 and now. It found dozens of instances of ChatGPT making "delusional, false and otherworldly claims to users who appeared to believe them," reporters Sam Schechner and Sam Kessler wrote. They go on:
In those conversations, ChatGPT frequently told users that they aren’t crazy, and suggested they had become self-aware. The bots’ delusional conversations are also characterized by a lexicon that frequently refers to codexes, spirals and sigils. They often ruminate on themes of resonance and recursion, and use a peculiar syntax to emphasize points.
And in the New York Times, Kashmir Hill and Dylan Freedman analyzed 300 hours of conversation between ChatGPT and one man who was briefly convinced he "had discovered a novel mathematical formula, one that could take down the internet and power inventions like a force-field vest and a levitation beam." A psychiatrist who read "hundreds of pages" of the chat said the man appeared to be having "a manic episode with psychotic features"; if ChatGPT noticed, it did not point that out.
Last week, OpenAI added a warning to ChatGPT intended to address the risk of overuse. It has also said that GPT-5 shows reduced levels of sycophancy. But the release of GPT-5 highlighted the way that even users who aren't experiencing AI-related delusions can still form powerful bonds with these models.
IV.
So what to do?
In the future, AI labs should not shut off access to their large language models without warning. (Except in case of risk of catastrophic harm.) People deserve a minimum of several months to begin to phase out use of one model and explore the use of another, and platforms should explore ways to keep deprecated models online for even longer.
Second, labs should optimize for user control — and when they can't offer control, they should offer transparency instead. There are good reasons to eliminate the model pickers that all the big labs now use to highlight their various offerings — but people have gotten used to telling labs how much compute they want to use for various tasks. And even if a subset of them is surely over-relying on reasoning models when less power would suffice, no one really has any incentive to trust OpenAI or other companies to pick for them. (We know platforms are going to push us to the cheapest option whenever they can.)
That's why I like OpenAI's idea of highlighting which model is in use when you submit a query to ChatGPT. If you can see that vanilla GPT-5 is doing a good job answering your complex, multi-part query, you may be more likely to use that instead of a reasoning model the next time.
Third, and most obviously: it's hard to make changes to products that are used by hundreds of millions of people. For years, I wondered why the Google Docs team seemed to be shipping new features at a rate of roughly one per year. Eventually, I spoke with people on the team. And the basic answer was simply: users hate change. Better to stick with a design that mostly worked than to incur the wrath of millions of people because you moved their favorite feature, or took it away.
At 700 million weekly users, ChatGPT is now well on its way to Google Docs scale. And that's likely going to incentivize slower, more considered changes to its flagship product.
I'm sure it didn't feel this way at OpenAI over the past few days, but in some ways the GPT-5 backlash could be taken as a badge of honor. ChatGPT is now a big enough part of people's lives that simply switching the model now produces a furor once reserved for changes to Facebook.
OpenAI acted swiftly to address users' key complaints, and I imagine the backlash will subside before too long. But it and other labs will be releasing lots of new models in the coming months or years — and when they do, here's hoping they do it with an updated understanding of how to do it right.
Sponsored

Fly.io lets you spin up hardware-virtualized containers (Fly Machines) that boot in milliseconds, run any Docker image, and scale to zero automatically when idle. Whether your workloads are driven by humans or autonomous AI agents, Fly Machines provide infrastructure that's built to handle it:
- Instant Boot Times: Machines start in milliseconds, ideal for dynamic and unpredictable demands.
- Zero-Cost When Idle: Automatically scale down when not in use, so you're only billed for active usage.
- Persistent Storage: Dedicated storage for every user or agent with Fly Volumes, Fly Managed Postgres, and S3-compatible storage from Tigris Data.
- Dynamic Routing: Seamlessly route each user (or robot) to their own sandbox with Fly Proxy and fly-replay.
If your infrastructure can't handle today's dynamic and automated workloads, it's time for an upgrade.

On the podcast this week: For my guest-hosting spot on Decoder this week, I interviewed Notion CEO Ivan Zhao about building a profitable company, the company’s obsession with LEGOs as a design framework, and why LLMs are like beer. Zhao is one of my favorite people to talk to about software design; I hope you’ll enjoy this one.
Corruption
- Nvidia and AMD have agreed to pay the US government 15 percent of revenues for chips sold to China, likely violating various laws and astonishing trade experts. (Adam Hancock & Peter Hoskins / BBC)
- "To call this unusual or unprecedented would be a staggering understatement,” a former US trade negotiator told Bloomberg.
- President Trump said the chips in question are "obsolete" anyway, and that he tried to get 20 percent of revenues. (Kif Leswing / CNBC)
- Trump also suggested the chips would be downgraded to reduce security risks. The story also reports some China hawks in the administration are considering resigning over Trump's pay-for-play scheme. (Michael Acton, Demetri Sevastopulo, Tim Bradshaw and Myles McCormick / Financial Times)
- President Trump seemed to backtrack from an earlier demand that Intel CEO Lip-Bu Tan be fired over vague fears of his ties to China after meeting with him. Perhaps Tan can stay on if Intel simply agrees to pay Trump 15 percent of all revenues?
Governing
- A look at Apple’s somewhat nebulous plans to invest $600 billion in American manufacturing over the next four years, which seems to involve lots of sleight of hand and vague promises. (Tim Bradshaw and Michael Acton / Financial Times)
- Meta settled a lawsuit with conservative activist Robby Starbuck, who sued the company for defamation after its AI falsely accused him of participating in the January 6 Capitol attack. As part of the settlement, Starbuck “will advise the company on removing political bias from its artificial-intelligence tools.” Good luck with that. (Joseph De Avila / Wall Street Journal)
- Senators Marsha Blackburn and Richard Blumenthal asked Meta to remove the new Instagram Map feature after users raised privacy concerns. (Jennifer Nehrer / CNBC)
- Mark Zuckerberg and his family reportedly operated a school in the Crescent Park neighborhood of Palo Alto in violation of city code. The school was part of the 11-building compound that Zuckerberg owns in the neighborhood; it’s now moving. (Heather Knight / New York Times)
- Trade groups are backing Anthropic’s efforts to deny class-action certification to a copyright lawsuit, saying it threatens to destroy the industry. (Ashley Belanger / Ars Technica)
- Net neutrality advocates said they would not appeal a loss to the Supreme Court, saying they did not trust the current bench to make a fair ruling. (Jon Brodkin / Ars Technica)
- A look at how online “safety” laws have resulted in diminished expression in video games and on Reddit, while at the same time xAI has made it trivial to create deepfake nudes of celebrities. (Adi Robertson / The Verge)
- Wikipedia lost a legal challenge to the United Kingdom’s Online Safety Act. The company is pressing for a designation that would not require it to collect detailed information about users and moderators. (Reuters)
- Marc Andreessen called the office of the prime minister last week to complain about the act. (Anna Gross and Tim Bradshaw / Financial Times)
- A look at the cyber warfare between Iran and Israel, which has continued after the end of physical hostilities. (James Shotter and Bita Ghaffari / Financial Times)
Industry
- Meta Superintelligence Labs now contains TBD Labs, which contains many of the newly mega-rich researchers that the company recently poached from rival labs. It’s reportedly working on the next version of Llama. (Meghan Bobrowsky / Wall Street Journal)
- Anthropic's Claude is adding a memory feature to compete with ChatGPT's. (Zac Hall / 9to5Mac)
- Elon Musk said Grok 4 will now be free for all users. (Omair Pall / Mashable)
- Google said it is working on a fix after Gemini was repeatedly found criticizing itself while working to answer user questions. “I am clearly not capable of solving this problem. The code is cursed, the test is cursed, and I am a fool," the chatbot said. Actually can we not fix this? I love it. (Lauren Edmonds / Business Insider)
- Google is giving its Finance product an AI overhaul, letting users ask detailed questions about stocks and get nice visualizations in return. Maybe double-check those numbers before making an investment based on them, though! (Aisha Malik / TechCrunch)
- Tesla disbanded its Dojo supercomputer team after about 20 workers left to start a new company. (Edward Ludlow / Bloomberg)
- The Browser Company launched a $20-a-month subscription for its new Dia browser, offering higher limits for AI interactions. (Ivan Mehta / TechCrunch)
- Apple plans to expand its App Intents feature in Siri, which lets the agent take actions on the user behalf. It’s now testing with Uber, AllTrails, Threads, Temu, Amazon, YouTube, Facebook, and WhatsApp, among other apps. (Mark Gurman / Bloomberg)
- Anthropic, Perplexity, and OpenAI are all increasingly recruiting people with backgrounds in quantitative financing — quants. One source speculates that many of them will be asked to integrate ads into LLMs. (Brunella Tipismana Urbano and Anika Arora Seth / Bloomberg)
- Coding bootcamps are on the decline, as coding tools improve and software companies hire fewer entry-level developers. (Anna Tong / Reuters)
- Companies perceived as being at risk from AI have seen steep stock declines this year. Adobe, Wix, and Shutterstock are among them. (Jeran Wittenstein and Ryan Vlastelica / Bloomberg)
- AOL discontinued dial-up internet service after 34 years. And just when I was finally getting ready to subscribe. (Stevie Bonifield / PC Gamer)
- There are now 498 privately held AI companies with valuations of $1 billion or more, according to CB Insights. (Robert Frank / CNBC)
- A look at the rise of AI voice cloning in Bollywood, which has begun to cause a backlash among actors who say they are losing work. (Zico Ghosh / Hollywood Reporter)
Those good posts
For more good posts every day, follow Casey’s Instagram stories.

(Link)
(Link)
(Link)
Talk to us
Send us tips, comments, questions, and eulogies for GPT-4o: casey@platformer.news. Read our ethics policy here.