The reporter who tried to replace herself with a bot
Anxiety about AI replacing entry-level jobs is on the rise. Could a state-of-the-art chatbot do the job of a Platformer fellow? PLUS: Anthropic vs. OpenAI, and will AI kill SaaS?

Editor's note: Last week our fellow, Ella Markianos, pitched me on a novel experiment: attempting to use AI tools to do as much of her job as possible, and writing about the results. As her editor I can say with confidence that Ella is irreplaceable, and her job is hers as long as she wants it. Still, like Ella, I was curious what her investigation would find. Today, we publish her report. — Casey
As a young AI journalist, I spend a lot of time following the workers whose jobs are threatened by AI: recent CS grads, writers, people in entry-level roles. The ongoing collapse of the journalism business, highlighted by this week’s terrible cuts at the Washington Post, only serves to make those fears more acute.
As it so happens, I myself am a recent computer science grad in an entry-level writing role. And while we don’t yet have robots that can do on-the-ground reporting, large language models are becoming increasingly proficient at many of the tasks I am assigned each week.
One of my core responsibilities at Platformer is among the most computer-based tasks you can imagine. Along with my colleague Lindsey Choo, I write our Following section. In Following, we explain a news story and share what prominent people are saying about it on the internet.
I’ve long been worried that AI could upend the career in journalism that I’ve only just begun. My doubts are severe enough that I’ve spent hours wondering whether I should be pivoting toward my other skills. My totally irreplaceable skills, like… coding.
And so I did what anyone would do in my situation: size up my competition. I spent 20 hours building and customizing a Claude-based AI journalism agent that I named “Claudella” and the next several days investigating how well it could do my job.
Staying up until 6AM making frantic adjustments to Claudella, I discovered the strange allure of vibe coding your own replacement. I built a system that integrates pretty smoothly with all the apps Platformer uses to work and imitates my writing voice surprisingly well. And I oscillated between being heartened by Claudella’s dumb mistakes and genuinely scared that Claudella could do my job.
I was surprised how much my results improved after I made a concerted effort to give Claudella good instructions about how I work.
That included basics like attaching a style guide and extensive examples of the writing I wanted. It also included finicky fixes for helping my fledgling agent’s challenged search abilities.
By the end, I was surprised by how accurate Claudella’s work was, and how close its conclusions came to my own judgments.
It couldn’t write a one-liner to save its life. But it was ready for action.
Claudella’s first day at work
I wired up Claudella to shadow me on our work Discord. On day one, I gave it the same assignment I got from my editor.
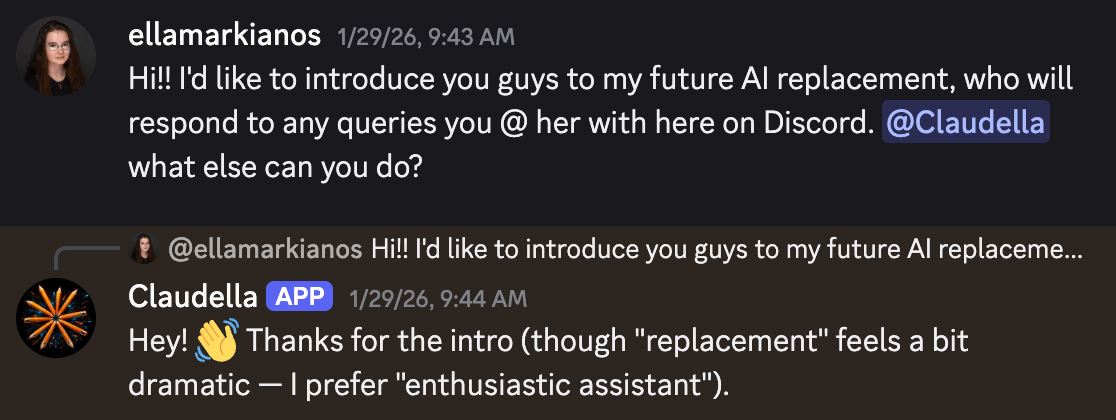
Claudella was a bit coy about her potential to replace me. But it took to the job quickly, instantly taking on her new assignment.
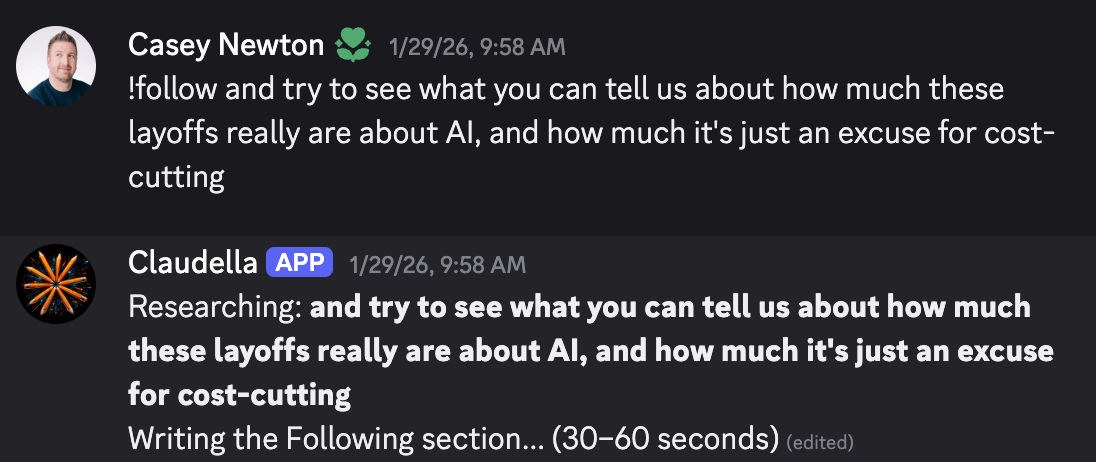
Claudella’s turnaround rate was a lot faster than mine, although it tended towards two minutes instead of the 30 to 60 seconds that it promised Casey when he asked (rude).
Unfortunately, Claudella’s first assignment went south quickly. For one thing, the bot failed to realize that I’d already sent it a PDF it was asking for. For another, it immediately ran out of Anthropic API credits and refused to continue working until we rectified the situation.
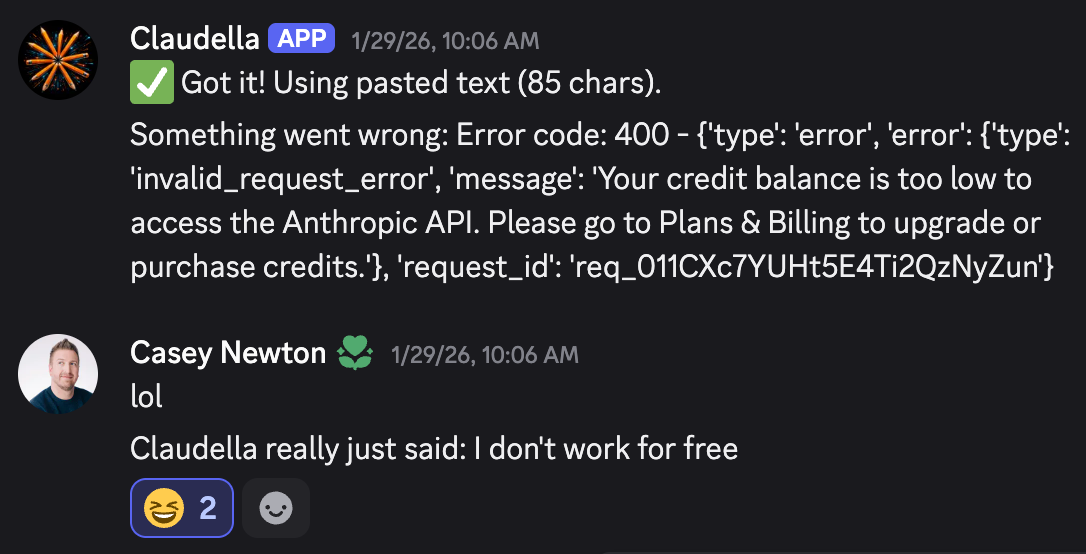
I forked over the cash for some additional API credits. But Claudella’s second draft was also a dud, thanks to a random technical issue.
We organize the links in each edition of Platformer in a Notion database, and mark them as “used” once they have made it into a draft. Claudella skipped over the used links when writing news briefs, causing it to miss important information. I know to use all the relevant links, but my fledgling agent wasn’t equipped to do that.
By the third draft, though, Claudella was turning heads. Lindsey reported that she was surprised by how well my creation did our job. And despite a few errors, I was pretty happy with Claudella’s work myself. The bot wisely agreed with me that many “AI-related” layoffs were just spin from CEOs looking for cover, and it found some relevant X posts I hadn’t managed to find myself.
Claudella’s second day at work
After a solid first day, I decided it was time for Claudella to try its hand at a storied benchmark in the history of AI: the Turing test.
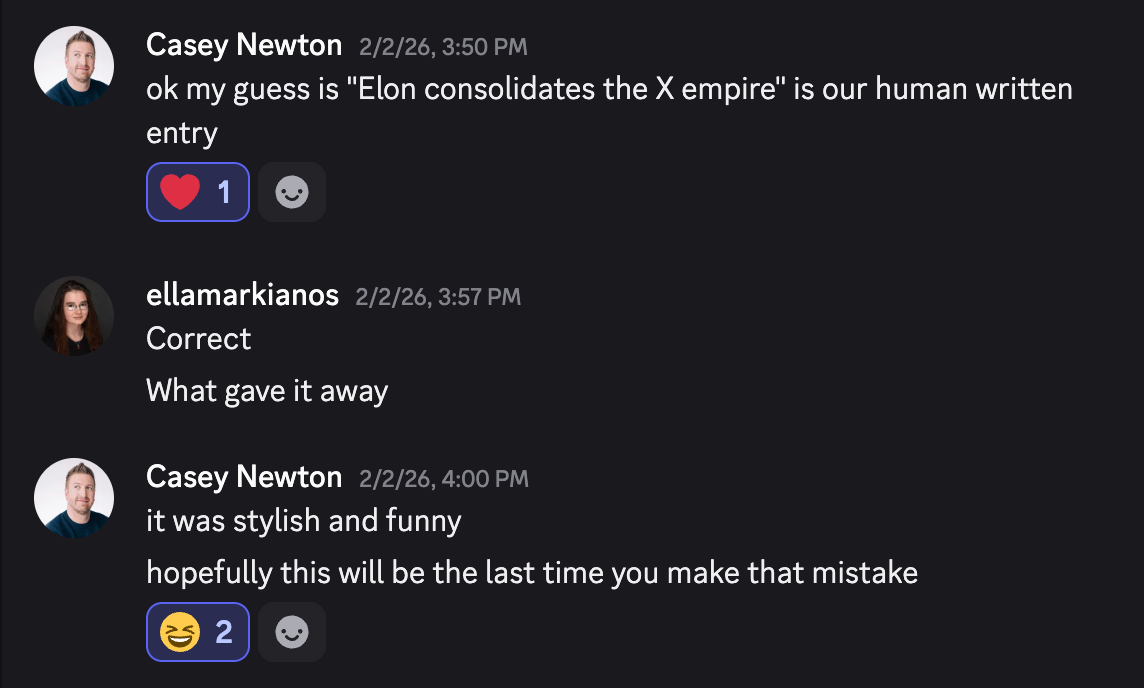
I would present two versions of Platformer’s Following section for the day to Casey: one, the genuine human-written piece that would go in the newsletter; the other, an AI counterfeit. I asked Casey to guess which was which. Thankfully, this time Claudella’s first draft was good enough to submit for consideration.
I turned in Lindsey's and my painstaking creation, “Elon consolidates the X empire,” alongside Claudella’s rapidly generated effort, “Musk’s $1.25 trillion mega-merger.”
There were no glaring hallmarks of AI writing in the latter: nary a “you’re absolutely right” was in sight, and Claudella’s use of em dashes was no more egregious than mine. As the moment of judgment arrived, I wondered if there was anything that would give away the AI authorship — or if I really might be cooked.
As it turns out, I needn’t have worried.
This time, I think the real giveaway was our “Why we’re following” subsection, where we collect online commentary. Despite me feeding Claudella a bunch of examples from previous editions, the model drifted toward a very sincere and verbose style, adding lots of unnecessary detail. (I tend to go more concise and sarcastic.)
I wrote three sentences for my version, and Claudella wrote seven. My ending line had been, “We hope he will use his power wisely (as he has failed to do in the past).” Claudella’s was “Meanwhile, xAI is facing a host of new regulatory probes, including by authorities in Europe, India, Australia and California, after its Grok AI tools enabled users to easily generate and share sexualized images of children and non-consensual intimate images of adults.”
The earliest version of Claudella would often hallucinate; I fixed that by adding very strict sourcing instructions to my prompts. But the new version would sometimes link to an article that didn’t support its (true) claims. That’s the sort of error that editors find annoying to track down and fix.
What a bot can't do
I could view the Claudella experiment through the lens of human exceptionalism and say that my bot is missing the style and humor that can only spring forth from the human soul. I might say that it occasionally hallucinates because it lacks “real intelligence.” But I think a lot of what's missing will simply be fixed by improvements in what the AI companies call “instruction following.”
I saw a version of this myself. Claudella improved significantly after I gave it examples and a step-by-step guide to catch the errors it was making. The process was not unlike the mentoring I receive when Casey and I talk about my writing. But because I’m working with a text-based language model, Claudella always needs written instructions.
Unfortunately, at a certain point too many instructions make the system start behaving erratically. It gets confused by my micromanaging. For example, I wanted Claudella to evaluate our commentary roundup for length, shortening it if there weren’t any particularly juicy posts that day. But when I explicitly asked for concision, the model got confused and forgot to write the roundup section altogether.
This could make me hesitant to give Claudella the feedback it dearly needed — that it was being too serious and too wordy for the task at hand. In those cases I said nothing, because I didn’t want to upset the rickety pile of sticks that held my fledgling AI journalism agent together.
Properly solving these issues might require AIs to do “continual learning” analogous to the way humans do — receiving regular feedback and incorporating it into how they work.
Although continual learning is currently a major focus for AI researchers, I suspect many shortcomings will be patched just by improving AIs’ ability to process more written instructions.
Which brings us to today.
Claudella 4.6
Fortunately, I had a perfect opportunity to see how a change in AI capabilities would affect the AI’s ability to do my job: Anthropic released an update to Claude this morning. I decided to test my original agentic setup with the new model.
My first test was of the new model’s sense of humor. Asked to make a joke about a research task I had given it, 4.5 landed a better one-liner than 4.6 did, at least in my opinion.
I then repeated the key task I had given 4.5 earlier in the week: to write one of today’s Following items. And I set up a blind taste test by having Claude Code rename and reset the time stamps on the files for me so I couldn’t tell which was which.
But the result was obvious from the start. Even headlines were of noticeably different quality. One had written “AI-fueled panic wipes $285 billion from software stocks” as its title. The other went with “Welcome to the 'SaaSpocalypse',” which is more my style. (Sometimes, seeing myself reflected in Claude reminds me how annoying I am.)
I was a bit disappointed with the “wipes $285 billion” article. While it hit the right beats, it also included some extraneous details, such as when it decided to list the names of all 11 Cowork plugins Anthropic released this week (shill much, Claudella?). It also failed to add line breaks to our commentary roundup, which made it unreadable.
My other Claudella handled the line breaks. Its style was closer to my own, offering more cheek and drama (e.g. “The fear gripping Wall Street is fundamentally about whether AI is about to eat the software industry alive.”) It also included three of the same quotes I had chosen in my own roundup.
This second model — which turned out to be 4.6 — was clearly the winner. The Opus 4.6 update followed my instructions better, and produced writing that was far more stylish.
It still has a ways to go: about half of the piece needed to be cut, and the model had a penchant for ten-dollar words and amplifiers like “fundamentally” that I found annoying. And you can’t judge a model’s true quality by a single day of testing.
Still, there was something unsettling about feeling the AI frontier advance under my feet just a few days into this experiment.
What I learned
I went into this project with some anxiety about whether AI is poised to take my job. Overall, this experiment exacerbated my fears. In important ways, Claudella can do my job.
But it also has clear shortcomings. In particular, it has trouble understanding which parts of a style are important to replicate. It also struggles to respond to editor feedback. And when asked to write about AI, the Claude-based model shows a notably favorable bias toward Anthropic. (Which makes a second Anthropic-related conflict of interest for us here at Platformer. Casey’s boyfriend works there. Perhaps you’ve heard?)
Still, the bot’s work sometimes impressed me. And I saw a clear advance in ability today even from a relatively minor model update.
While I enjoyed seeing my AI agent get better at my job, I don't feel any desire to delegate my writing to it. I wouldn’t do it even if readers would accept it. As well as my AI mentee can now write, drafting is what I do to think. If I had Claude write my first drafts, even if I fact-checked them thoroughly, it would be a lot harder to tell whether the angle was my own view or the AI’s.
Still, I’ve decided to keep Claudella around. The bot excels at clip searches — looking for important quotes and analysis I might have missed. And I want to keep an eye on how quickly its skills improve.
And for me? The truth is that I’m less married to the idea of a career in journalism than I was at the beginning of this experiment.
I’ve had many conversations with my fellow AI reporters about what moats we might have against the advancement of AI automation. Chief among them are developing relationships with human sources, reporting on scenes in person, and getting scoops that people wouldn’t entrust an AI with.
But the things I love most about AI reporting are having an excuse to read really long computer science papers and then writing about them. I worry that if AI becomes a great writer and research assistant, AI journalism will mostly become about networking.
Regardless, I won't stop reading weird CS papers. And I won't stop writing. Not because I'm confident these skills will keep me employed, but because they're what I actually like doing.
Sponsored
One in Five LLM Answers Was Russian Disinformation. Until Guardrails Were Turned On.

In a recent test, NewsGuard’s guardrails fully detoxed AI models from hostile disinformation. When red-team analysts overlaid two NewsGuard datasets on a commercial LLM, all false claims seeded by Russian influence operations were eliminated. Without these safeguards, the same prompts caused the top 10 chatbots to produce Russian disinformation 1 in 5 times.
By combining publisher-reliability data and real-time false-claim fingerprints, NewsGuard provides the first scalable solution to prevent LLMs from being exploited by malign influence operations.
If you care about AI trust, safety, and responsible deployment, this report shows exactly how to secure your models by licensing NewsGuard’s protection against foreign influence operations.
Contact NewsGuard at partnerships@newsguardtech.com.

On the podcast this week: Moltbook founder Matt Schlict joins us to discuss the future of AI agents. PLUS: Kevin and I sort through SpaceX's acquisition of xAI, and we play around with Google's Project Genie.
Apple | Spotify | Stitcher | Amazon | Google | YouTube
Following
Anthropic and OpenAI duel over models and ads
(See ethics disclosure!)
What happened: It's like a Super Bowl for nerds: Anthropic and OpenAI today released dueling enterprise-focused LLMs that improve on their previous agentic coding capabilities.
Claude Opus 4.6, Anthropic’s newest model, focuses more on “the most challenging parts of a task without being told to,” the company says, and “stays productive over longer sessions.” One notable addition is “agent teams,” which allow a user to split work across multiple agents and assign them different jobs.
Opus 4.6 is an upgrade for those looking to use it in law, finance and cybersecurity, Anthropic said. It scored the highest BigLaw Bench score of any Claude model at 90.2%, and is better at scrutinizing company data, regulatory filings, and market information. The model has already found more than 500 previously unknown high-severity security flaws in open-source libraries, Anthropic told Axios.
Across town, OpenAI unceiled GPT-5.3-Codex. The company said it improves on the coding capabilities of its predecessor, GPT-5.2-Codex, and on the reasoning and knowledge capabilities of GPT-5.2. The new model also runs 25 percent faster than previous models, and was the company’s “first model that was instrumental in creating itself,” it said. Rounding out the hype, OpenAI says 5.3 can go beyond coding to “do nearly anything developers and professionals can do on a computer.”
Speaking of the Super Bowl: the simultaneous release of the two models comes amid a very public fight over Anthropic’s debut ad for the Big game, where the company took aim at the idea of ads in chatbots like ChatGPT — and explained its decision to not have ads in Claude in an accompanying blog post.
In response, OpenAI CEO Sam Altman penned a scathing X post, where he called the ad “clearly dishonest.” “We would obviously never run ads in the way Anthropic depicts them. We are not stupid and we know our users would reject that,” Altman wrote.
Why we’re following: Anthropic's Super Bowl ad didn't mention any competitors by name, but still seemed notably more punchy than the company's typical communications. And it's fair to ask whether it was a tactical mistake — if you truly believe ads are going to ruin your competitors' products, why not let it simply happen? Never interrupt your enemy while he's making a mistake and all that.
But Altman's aggrieved response may have justified the approach, if only in hindsight. Pushed into doubling down on an approach he had previously called a "last resort," Altman was left pushing the dubious idea that Anthropic's $20-a-month product is "only for rich people" and its move to cut competitors off from its coding tools is "authoritarian" in nature. Anthropic could not have asked for better earned media, and the Super Bowl hasn't even happened yet.
As for the dueling models: it's too early to say which is superior for coding and other tasks. In limited early testing, Casey found 4.6 to represent a meaningful step forward at writing tasks — a meaningful step forward over 4.5, which was itself a notable improvement over its predecessor. Codex we are still (candidly) getting the hang of.
What people are saying:
“Anthropic vs openai is like kendrick vs drake but for nerds,” wrote @sonofalli on an X post that has garnered more than 180,000 views.
Altman’s lengthy Super Bowl ad crashout set off a firestorm of jokes, many of them not in his favor. @paularambles highlighted the silliness of the entire feud on X: “the best minds of my generation are thinking about ads about ads.”
“Can’t believe anthropic rage baited the guy and he fell for it. he’s even using capital letters in this tweet, they broke him,” @alxfazio posted.
@robj3d3 posted an excellent meme:
“sama: "Anthropic's ads are not a threat"
also sama:

—Lindsey Choo and Casey Newton
People are worried that AI will kill SaaS
What happened: A release of legal tools in Anthropic’s Cowork product triggered a big software stock selloff.
It's the latest chapter in months of software companies’ stocks declining as fears of AI disruption mount; the IGV Software Index has dropped 30% since September.
Spurring these declines is anxiety that AI coding might soon substitute for the enterprise software these companies make their money on. Companies including Microsoft and ServiceNow have reported underwhelming revenue this quarter, which doesn’t help.
But SaaS companies aren’t the only ones having a bit of trouble. The Financial Times reports that chip company Arm has dropped 8% because their revenue report came in only slightly higher than analysts’ forecasts. They stand to benefit from AI, given their CPU designs are in high demand as a component for data centers. But in a period of high anxiety about tech stocks, apparently that's not enough.
Why we’re following: AI definitely can do some impressive coding. But there isn’t clear evidence that the coding software AI companies are making substitutes for the specialized enterprise software SaaS companies sell. (Or for the logistical services and customer support that are often needed to make SaaS work in most organizations.) Professional software is valuable in large part because of its reliability. While we've seen plenty of cool AI coding projects, we haven’t yet seen evidence that they can substitute for the total package that good SaaS companies are selling to their customers.
At the same time, AI coding has gotten dramatically better in the past few years, and presumably that trend will continue. We can’t entirely blame sellers for extrapolating an upward trend.
What people are saying:
Arm’s CEO René Haas called the dip in tech stocks a “micro-hysteria,” suggesting it came from a misunderstanding of the impact AI is having on software, in an interview with the FT.
On X, Garry Tan, CEO of startup incubator Y Combinator, said that software absolutely has a future. But to realize that future, it needs to incorporate AI agents. “Software is not dead," he wrote" SaaS without agents may suffer, but Agent SaaS is alive, well, and winning.”
Nvidia CEO Jensen Huang still believes in SaaS, too. “There’s this notion that the software industry is in decline and will be replaced by AI,” Huang said at Cisco Live. “It is the most illogical thing in the world, and time will prove itself.”
Added analyst Benedict Evans on Threads: "Every analyst and everyone who knows anything about enterprise software today: 'I can’t believe I actually have to explain why this death of SaaS thing is stupid.'”
—Ella Markianos
Side Quests
OpenAI introduced OpenAI Frontier, an AI agent management platform.
OpenAI accused xAI of directing its employees to use messaging tools that auto-delete communications after a time period and destroying evidence in its lawsuit. GitHub added Claude and Codex AI coding agents.
Several clouds are offering OpenClaw (formerly Moltbot/Clawdbot) as a service despite security risks.
Apple CEO Tim Cook said he will continue to lobby lawmakers on immigration and said he was “deeply distraught” with the US’s current immigration approach. It probably ruined MELANIA for him!
TikTok’s data center outage affected posts of all categories, not just political content, a new analysis found.
Senators Ruben Gallego and Bernie Moreno introduced the SCAM Act, a bipartisan bill that would require social platforms like Meta to vet their advertisers. Is there a good reason platforms should not have to verify their advertisers' identities? It's weird you have to verify your identity to open a bank account but not to shill crypto coins on Facebook.
A look at why AI companies are spending tens of billions to court the Indian market.
The UK will work with Microsoft to build a deepfake detection system.
Meta Superintelligence Labs product manager Megan Fu described the company’s new LLM, codenamed Avocado, as its “most capable pre-trained base model” in an internal memo.
Google beat its top and bottom lines in its fourth-quarter earnings report, and said it plans to double its AI spending this year to as much as $165 billion. The Gemini app has surpassed 750 million monthly active users. YouTube generated $60 billion in revenue for 2025, surpassing Netflix.
Amazon's stock dropped 10% after falling short of analyst estimates and announcing a massive increase to its planned capital expenditures. Reddit and Roblox posted earnings beats.
Egypt banned Roblox over child safety concerns. Roblox launched its anticipated 4D creation feature in open beta.
Snap beat expectations in its fourth-quarter sales and announced a $500 million stock buyback program.
Germany’s antitrust watchdog ordered Amazon to drop its price controls for retailers. Alexa Plus is now available to all US Prime members with an Alexa-enabled device. Amazon is reportedly discussing an OpenAI collaboration to power Alexa and other projects. The Amazon MGM Studio is developing AI tools to make movies and TV shows faster.
Spotify will start selling physical books and is introducing a Page Match feature to sync books in different formats.
Pinterest CEO Bill Ready fired employees who created an internal tool to track layoffs at the company.
Substack told users it discovered a data breach that compromised email addresses and phone numbers.
A look at how an Olympic snowboarder used AI to perfect her jump trick.
Those good posts
For more good posts every day, follow Casey’s Instagram stories.

(Link)
(Link)
(Link)
Talk to us
Send us tips, comments, questions, and entry-level AI jobs: casey@platformer.news. Read our ethics policy here.