Inside OpenAI’s new plan for fighting deepfakes
The company has new strategies for shoring up our shared sense of reality. Will they matter in the election?

On Tuesday, OpenAI joined the steering committee of a little-known but increasingly powerful standards body known as the Coalition for Content Provenance and Authenticity, or C2PA. In doing so, the company waded into one of the most critical debates about democracy in the age of artificial intelligence: how will we know that what we are seeing online is real? And what should tech companies do when they spot a fake?
With just under six months to go in the US presidential campaign, the biggest social networks have mostly managed to stay out of election coverage. With the top match-up a repeat of 2020, the candidates and their respective positions are well known by many voters. Whatever happens in November — and unlike in the epoch-shifting election of 2016 — it is difficult to imagine a scenario in which platform policies play a decisive role in the outcome.
At the same time, that doesn’t mean platforms will have an easy time this year. Elections affecting half the world’s population are scheduled to take place, and after years of layoffs, platforms will be monitoring them with much smaller trust and safety teams than they once had. And there’s at least one complicating variable that companies like Meta, Google, and TikTok have never had to manage in an election before: generative artificial intelligence, which threatens to overwhelm their platforms with synthetic media that could spread misinformation, foreign influence campaigns, and other potentials harms.
At this point, anyone whose Facebook feed has been taken over by Shrimp Jesus — or simply perused the best AI fakes from this year’s Met Gala — knows how easily AI-generated words and images can quickly come to dominate a social platform. For the most part, the outlandish AI images that have attracted media coverage this year appear to be part of a standard spam playbook: quickly grow an audience via clickbait, and then aggressively promote low-quality goods in the feed for however long you can.
In the coming weeks and months, platforms are likely to be tested by a higher-stakes problem: people attempting to manipulate public opinion with synthetic media. Already we’ve seen deepfakes of President Biden and Donald Trump. (In both of those cases, incidentally, the perpetrators were connected to different rival campaigns.) Synthetic media targeted at races at the local, state, and national level is all but guaranteed.
In February, the big platforms signed an agreement at the Munich Security Conference committing to fight against deepfakes that attempt to deceive voters.
But with a flood of fakes expected to begin arriving any week now, what steps should Instagram, YouTube, and all the rest be taking?
There are two basic tasks here for the tech companies: figure out what’s fake, and then figure out what to do about it
The first, and arguably most difficult task for platforms is to identify synthetic media when they see it. For a decade now, platforms have worked to develop tools that let them sniff out what Meta calls “inauthentic behavior”: fake accounts, bots, coordinated efforts to boost individual pieces of content, and so on. It can be surprisingly hard to identify this stuff: bad actors’ tactics continually evolve as platforms get wise to them.
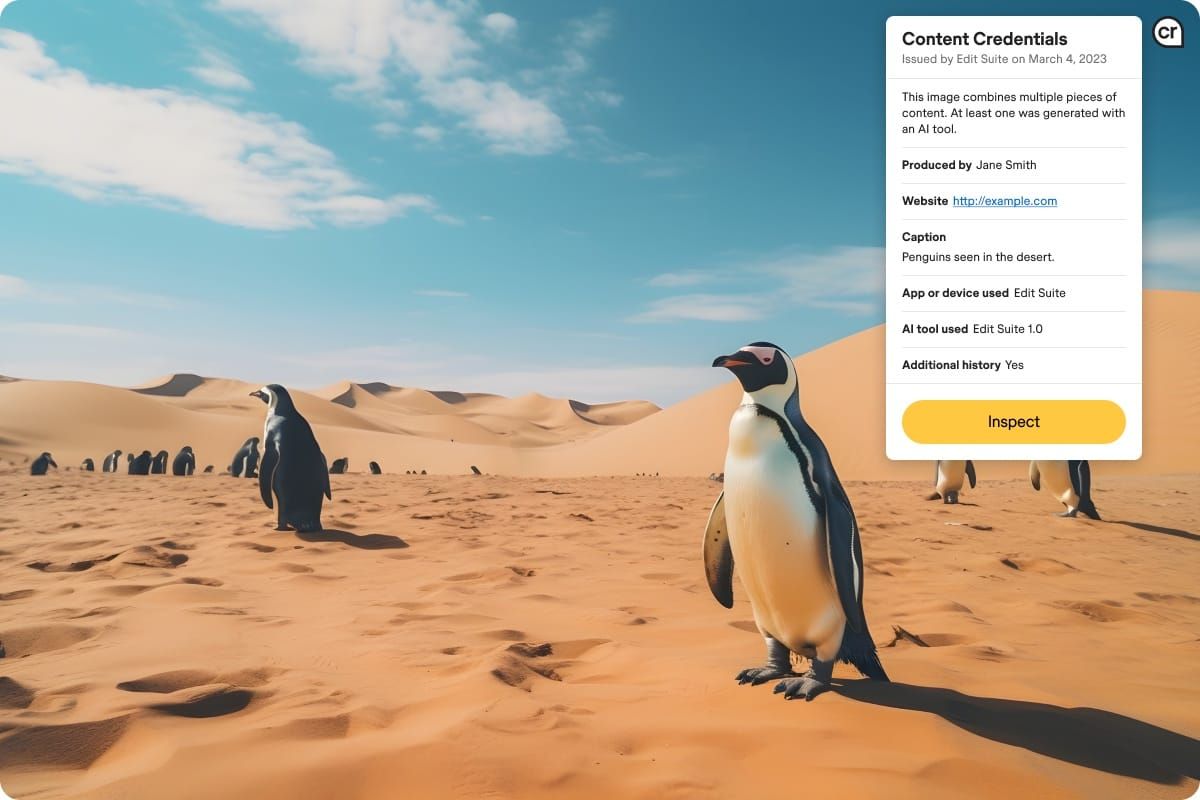
The C2PA was founded in 2021 by a group of organizations including Microsoft, Adobe, Intel, and the BBC. The goal was to develop a royalty-free, open technical standard that adds tamper-proof metadata to media files. If you create an image with Photoshop, for example, Adobe adds metadata to the image that identifies the date it was created, the software where it originated, and any edits made to it, among other information. From there, anyone can use a free tool like Content Credentials to see where it came from.
OpenAI said in January that it would begin adding this metadata to images created with its DALL-E 3 text-to-image tool and its Sora video generation tool. In joining the C2PA, the company is endorsing this metadata-driven approach to help tell what’s real from what’s fake.
“The world needs common ways of sharing information about how digital content was created,” the company said in a blog post. “Standards can help clarify how content was made and provide other information about its origins in a way that’s easy to recognize across many situations — whether that content is the raw output from a camera, or an artistic creation from a tool like DALL-E 3.”
Of course, there are some big flaws in any plan that relies on metadata. For one thing, most media uploaded to social platforms likely isn’t made with a tool that adds content credentials. For another, you can easily take a screenshot of an AI-generated image to eliminate its metadata.
To fully solve the problem, you need to try several different things at once.
OpenAI has a few different ideas on the subject. In addition to the C2PA, on Tuesday it also released a deepfake detector to a small group of researchers for testing. The tool can identify 98.8 percent of images made with DALL-E 3, the company said, but performs worse on images generated by rivals like Midjourney. In time, though, the company hopes it will serve as a check on media uploaded without content credentials — although they’re not sharing it with platforms like Facebook or Instagram just yet.
“We think it’s important to build our understanding of the tool much more before it’s let loose in the wild,” Sandhini Agarwal, who leads trustworthy AI efforts at the company, told me. Among other things, OpenAI is still working to understand how the classifier responds to different sets of images. For example, there are concerns that images from non-Western countries, which may be underrepresented in the tool’s underlying data set, might be falsely identified as fakes.
OpenAI is also exploring ways to add inaudible digital watermarks to AI-generated audio that would be difficult to remove. “Fingerprinting,” which allows companies to compare media found in the wild to an internal database of media known to be generated by their own tools, offers another possible path forward.
In the meantime, OpenAI and Microsoft said Tuesday that they would set aside $2 million for a digital literacy program designed to help educate people about AI-generated media.
“As we've been on a sort of listening tour to understand what the biggest concerns are leading up to elections in various countries, we’ve heard that there just aren’t high levels of AI literacy,” said Becky Waite, who leads OpenAI’s election preparedness efforts. “There’s a real concern about people's ability to distinguish what they're seeing online. So we're excited about this as an area of investment.”
No one I spoke with seemed certain that these approaches could collectively prevent the infocalypse. There are still technical breakthroughs to be achieved in order to create metadata that cannot be removed, for example. And it will take time for voters’ digital literacy to catch up to the state of the art. (Particularly since all these high-tech credentials remain mostly invisible to the average user.)
At the same time, you can begin to understand how platforms will soon use technology to build trust in what people are seeing in their feeds. A combination of metadata, watermarks, fingerprinting and deepfake detection should go a long way in determining the provenance of much of the content on social networks. That could be particularly true if platforms adopt policies that encourage people to share media that comes with those credentials.
What would those policies look like? One possibility is that platforms could create a system for digital content that resembles passport control. Just as most people are not allowed to cross borders without passports, someday social networks could choose not to display posts that arrive without credentials. Or, more likely, they could restrict this type of content’s reach: showing it to an account’s followers, for example, but making it ineligible for promotion in ranked feeds.
“There are tricky trade-offs to be made here,” said David Robinson, who leads OpenAI’s policy planning team. “I'm sure different platforms will make different choices.”
We’re already seeing hints of this: in March, YouTube added a way for creators to label their own videos as AI-generated; Meta followed suit with a similar approach last month. For now, platforms aren’t penalizing users for uploading AI-generated content, which is fine: most of it is relatively benign. As more pernicious forms of AI content begin to materialize on platforms, though, they may begin to consider more restrictive approaches.
“It’s not just a technical problem,” Agarwal told me. “I think that’s the crux of why it’s so complex. Because it’s not just about having the technical tools. It’s about having resilience across the stack. We’re one actor, but there are many others. This is a collective action problem.”
Governing
- TikTok sued the federal government as expected, arguing the divest-or-ban law was unconstitutional and violates the First Amendment. The complaint is 67 pages long and rehearses many of the arguments that we have discussed here in recent weeks. (Sapna Maheshwari and David McCabe / New York Times)
- Meta’s Oversight Board is taking on three cases with posts that include the phrase “From the River to the Sea,” in relation to the war in Gaza. Given how polarizing the phrase is, I'll be watching this one closely. (Oversight Board)
- Microsoft deployed a generative AI model that is disconnected from the internet. It’s for US intelligence agencies. (Katrina Manson / Bloomberg)
- Checking in with former Trump campaign manager Brad Parscale, who mastered Facebook in 2016, and now proclaims that his new AI-powered platform will change polling and campaigning. (Garance Burke and Alan Suderman / Associated Press)
- American and Chinese diplomats are planning to meet this month for tentative arms control talks over AI use. (David E. Sanger / New York Times)
Industry
- Apple announced new iPad Pros with OLED displays and its thinnest hardware yet, powered by the M4 chip, at its spring event. (Chris Welch / The Verge)
- The M4 chip is designed to power generative AI capabilities, the company says. (Joanna Nelius and Tom Warren / The Verge)
- The new iPad Air 6 will now come in two sizes, powered by the M2 chip. Hilariously, it is heavier than the iPad Pro. (Zac Hall / 9to5Mac)
- The Apple Pencil Pro was unveiled, which features a squeeze option with haptic feedback. You will never use the Apple Pencil, I promise. Take it out of your shopping cart. (Ben Lovejoy / 9to5Mac)
- A new Magic Keyboard for the iPad is lighter and thinner, and has a larger trackpad and function row. (Ryan Christoffel / 9to5Mac)
- Apple has reportedly been working on its own chip to run AI software in data center servers, in a project internally referred to as Project ACDC. (Aaron Tilley and Yang Jie / Wall Street Journal)
- OpenAI and magazine publisher Dotdash Meredith are partnering in a licensing deal that will bring content to ChatGPT and AI models to the publisher’s ad-targeting product. (Emilia David / The Verge)
- Google Cloud is now offering Google Threat Intelligence, a cybersecurity offering that provides faster protection with a simpler user experience. (Kyle Alspach / CRN)
- Meta’s new generative AI tools for advertisers will allow them to create full images instead of just backgrounds for product images. (Sarah Perez / TechCrunch)
- Amazon committed to spending $9 billion to expand its cloud computing infrastructure in Singapore over the next four years. (Olivia Poh / Bloomberg)
- Amazon is launching Bedrock Studio, a new tool to let organizations experiment with generative AI models and eventually build AI-powered apps. (Kyle Wiggers / TechCrunch)
- Substack is attempting to lure TikTokers to the platform by creating a new creator program that will turn TikTok channels into Substack shows. The company's continued drift into platform lock-in features is notable. (Taylor Lorenz / Washington Post)
- Reddit shares soared 14 percent after the company’s first-ever quarterly results beat analyst expectations. (Ashley Capoot / CNBC)
- Match Group is forecasting revenue below Wall Street estimates for its second-quarter results, as users pull back from spending on dating apps. (Reuters)
- Free music streaming app Musi, which draws from YouTube, is gaining popularity among high schoolers. But at least one major music label is reportedly considering legal action over copyright. (Kate Knibbs / WIRED)
Those good posts
For more good posts every day, follow Casey’s Instagram stories.
Awful news--there were 2 volumes of the collected work of Hegel in the library and the protestors broke in and left 2 more
— cantorsdust (@cantorsdust.bsky.social) May 4, 2024 at 10:44 AM
I think I speak for us all when I say ow my bones
— lanyardigan (@lanyardigan.bsky.social) May 4, 2024 at 1:45 PM

(Link)
Talk to us
Send us tips, comments, questions, and political deepfakes: casey@platformer.news and zoe@platformer.news.